Write your solutions to the following problems either by writing them on a piece of paper or on a tablet and scanning your answers as a PDF. Note that you are not allowed to use LaTeX, Google Docs, or any other digital document creation software to type your answers. Homeworks are due to Gradescope by 11:59PM on the due date. See the syllabus for details on the slip day policy.
Homework will be evaluated not only on the correctness of your answers, but on your ability to present your ideas clearly and logically. You should always explain and justify your conclusions, using sound reasoning. Your goal should be to convince the reader of your assertions. If a question does not require explanation, it will be explicitly stated.
Review the solutions to Homework 2. Pick two problem parts (for example, Problem 2a and Problem 4b) from Homework 2 in which your solutions have the most room for improvement, i.e., where they have unsound reasoning, could be significantly more efficient or clearer, etc. Include a screenshot of your solution to each problem part, and in a few sentences, explain what was deficient and how it could be fixed.
Alternatively, if you think one of your solutions is significantly better than the posted one, copy it here and explain why you think it is better. If you didn’t do Homework 2, choose two problem parts from it that look challenging to you, and in a few sentences, explain the key ideas behind their solutions in your own words.
Solution
Problem 2: Parallelogram Law (14 pts)
a)
(4 pts) Let \(\vec{u} = \begin{bmatrix} 3 \\ -6 \\ 0 \\ 2 \end{bmatrix}\) and \(\vec{v} = \begin{bmatrix} 2 \\ 1 \\ 4 \\ -2 \end{bmatrix}\). Compute the following quantities:
The statement above is called the parallelogram law of vectors.
Hint: The point of part a) was to give you a feel for which quantities are involved in this statement. Your proof should not use these values in particular. Instead, start with the left-hand side of the equation and use the properties of the dot product introduced in Chapter 3.3.
Solution
Since \(|\vec u|^2 = \vec u \cdot \vec u\), we can expand both \(|\vec u+\vec v|^2\) and \(|\vec u-\vec v|^2\) using the distributive property of the dot product, as mentioned in the hint. Below, we color \(\textcolor{orange}{\vec u\cdot\vec u}\) in orange, \(\textcolor{blue}{\vec v\cdot\vec v}\) in blue, and \(\textcolor{magenta}{\vec u\cdot\vec v}\) in magenta.
Note that the \(\textcolor{magenta}{+2\vec u\cdot\vec v}\) from the first expansion and the \(\textcolor{magenta}{-2\vec u\cdot\vec v}\) from the second cancel when we add them. Thus,
(3 pts) Why is the equality from part c) called the parallelogram law? Let’s explore.
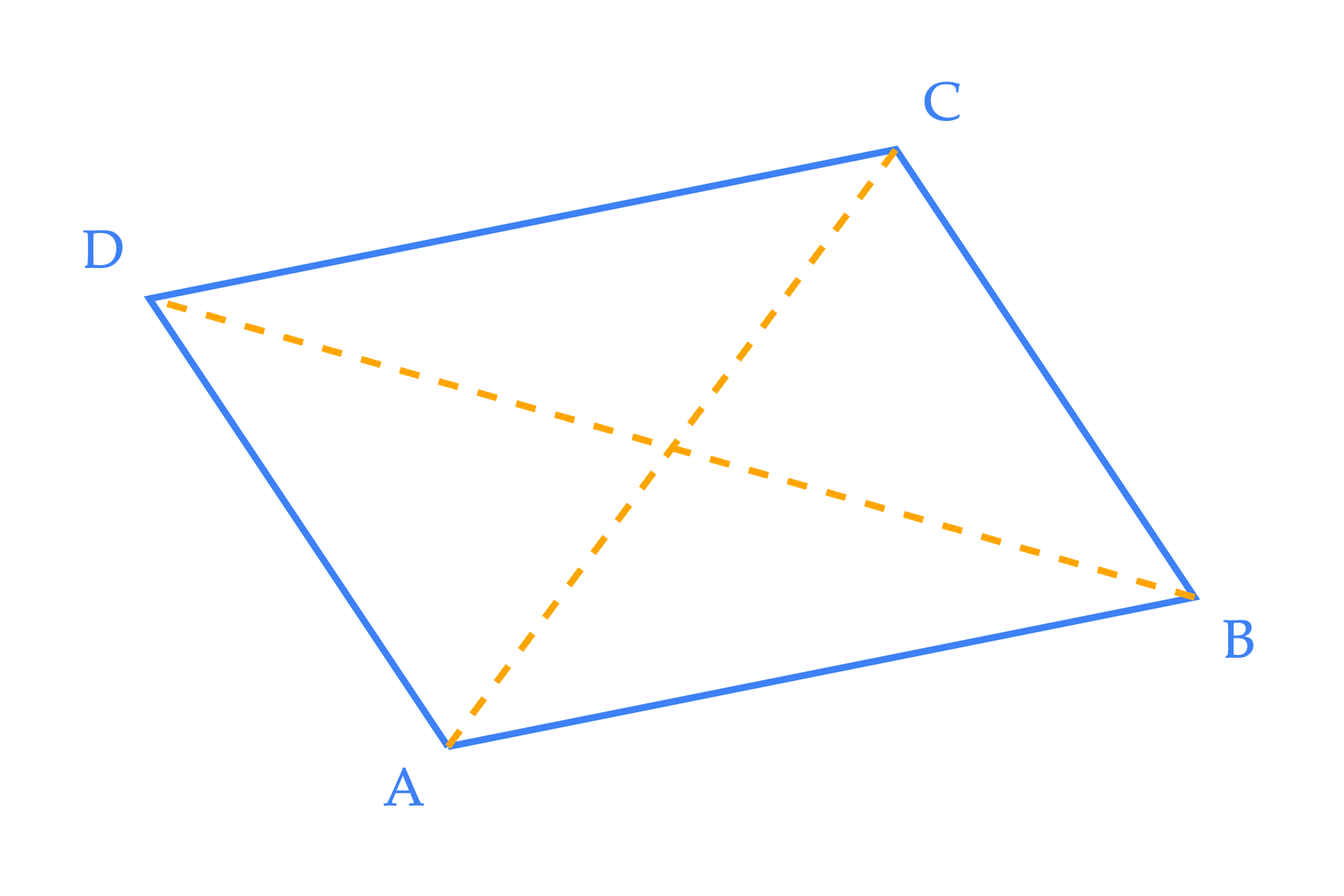
Suppose points \(A\), \(B\), \(C\), and \(D\) in \(\mathbb{R}^n\) form a parallelogram: a polygon with four sides where opposite sides are parallel and equal in length.
Using the results of the previous part of this problem, prove that the sum of the squares of the side lengths of the parallelogram is equal to the sum of the squares of the diagonals. In other words, prove that:
where \(AB\) represents the length of the segment from point \(A\) to point \(B\), etc.
Hint: Define two vectors, \(\vec u\) and \(\vec v\), and explain why the result from the previous part of this problem implies the desired equality. This is mostly an English problem.
Solution
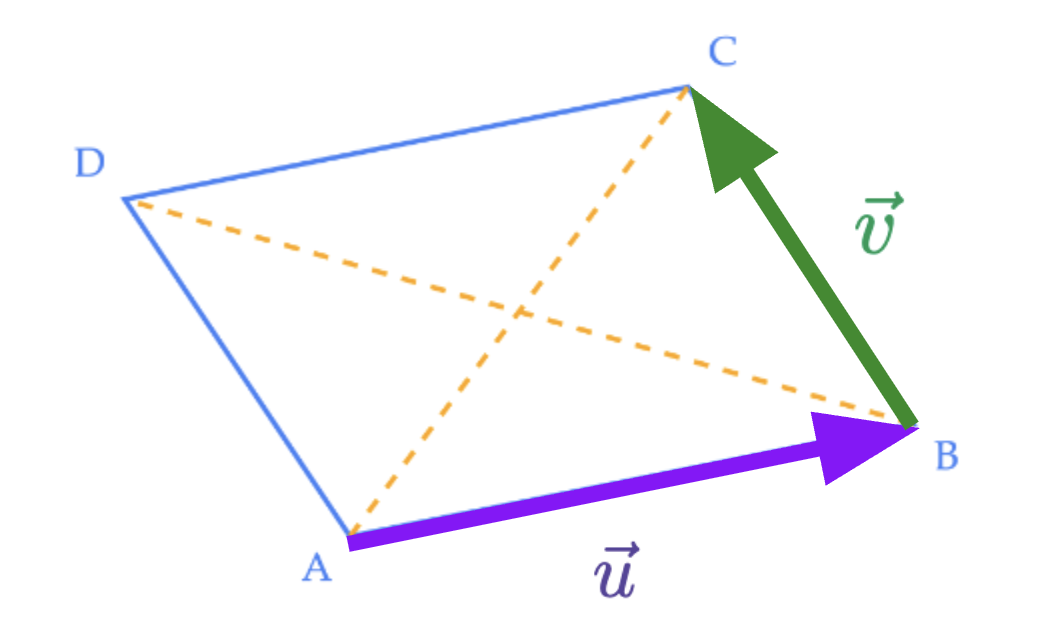
Let \(\vec u\) be the vector along \(\overrightarrow{AB}\) (purple arrow in the figure) and \(\vec v\) be the vector along \(\overrightarrow{BC}\) (green arrow).
Opposite sides of a parallelogram are equal and parallel, so the remaining sides point as
Much of our study of linear algebra involves understanding the set of possible linear combinations of a given set of vectors. As the notes detail, our multiple linear regression problem boils down to finding the best possible linear combination of the features, so it’s important that we understand how linear combinations work.
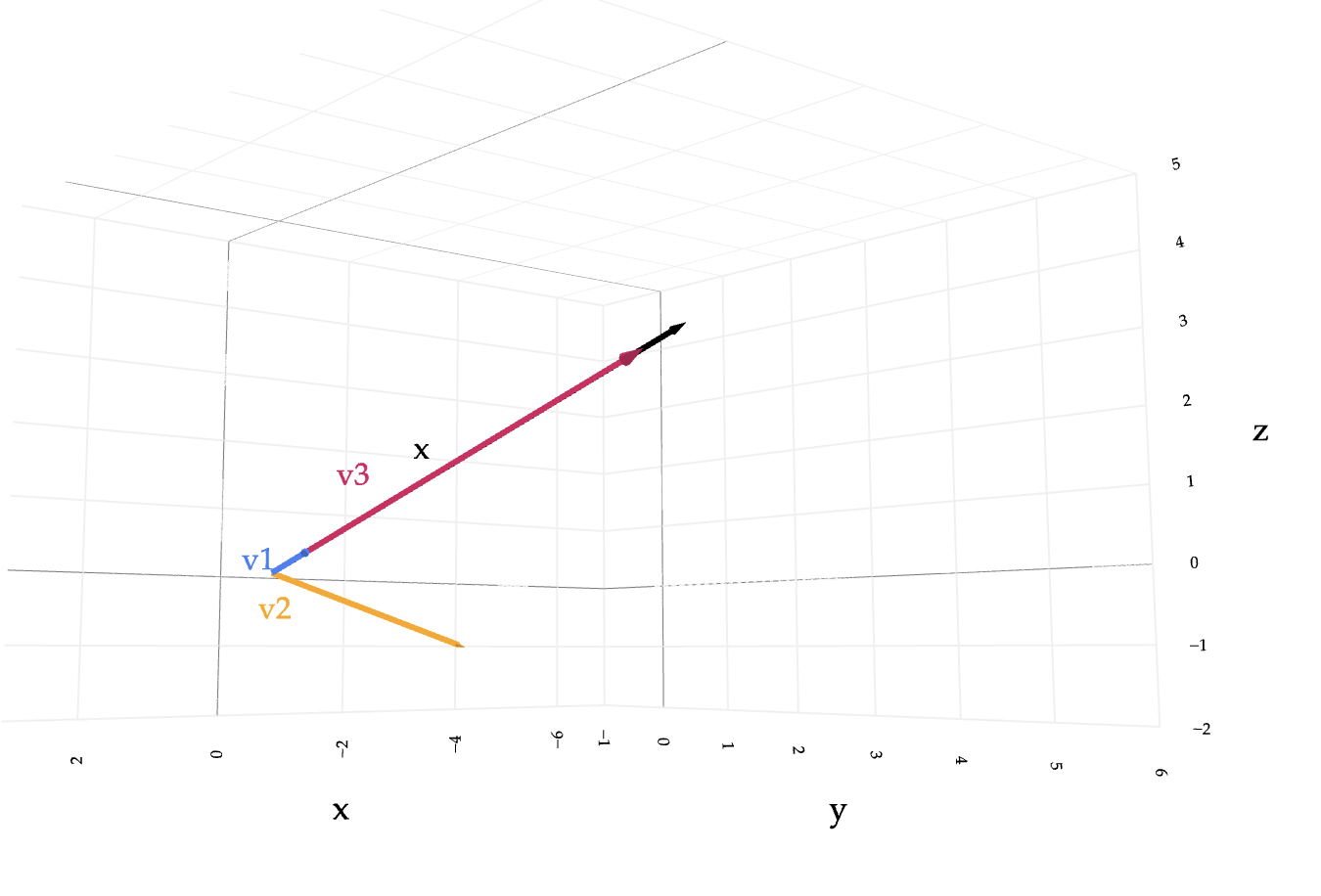
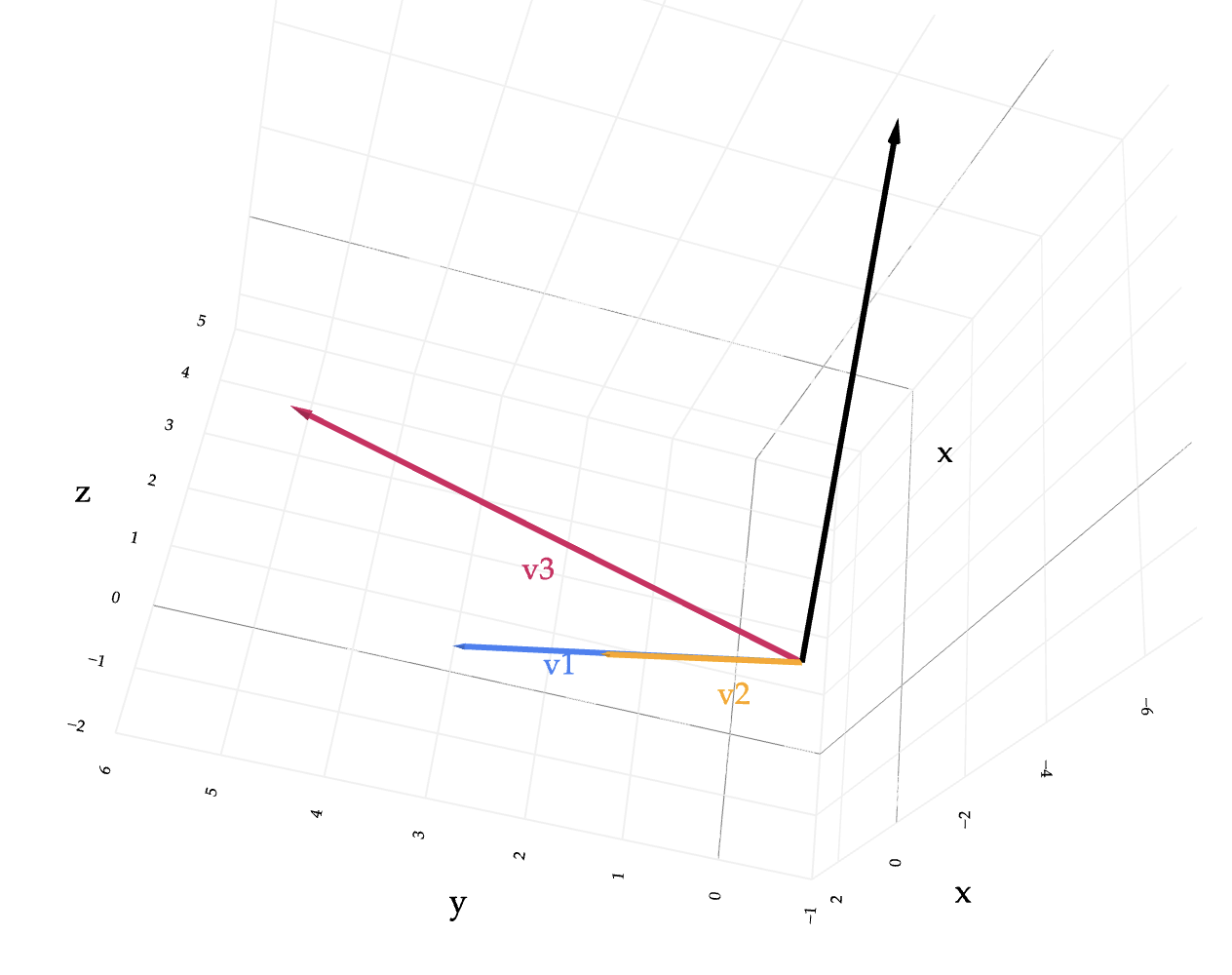
We recommend you have this visual open while you work through this problem.
a)
(4 pts) Find constants \(a\), \(b\), and \(c\) such that
$$ a \vec v_1 + b \vec v_2 + c \vec v_3 = \vec x $$
In other words, write \(\vec x\) as a linear combination of \(\vec v_1\), \(\vec v_2\), and \(\vec v_3\).
Hint: Start by writing out the equation as a system of equations. Then, use your favorite method for solving systems of equations to find \(a\), \(b\), and \(c\). We reviewed how to solve systems of equations in Lab 3.
Solution
\(a=-3, b=0, c=2\)
We can express the equation above as a system of three equations in the three unknowns \(a,b,c\).
(2 pts) Try and find constants \(d\) and \(e\) such that
$$ d \vec v_1 + e \vec v_3 = \vec x $$
If you are able to find constants \(d\) and \(e\), explain why, even though there are two unknowns but three equations for them. If you are unable to find constants \(d\) and \(e\), explain why no solution exists.
Solution
\(d=-3, e=2\)
This is a system of three equations and two unknowns, since there are only two vectors in the linear combination. We’ll start by solving it the same way we did in part (a).
so \((2)\) holds as well. Notice we did not need \((2)\) to find\(d\) and \(e\); it served as a consistency check, which it passes, so a solution exists.
You could also have seen this without re-solving: in part (a), the coefficient on \(\vec v_2\) was \(b=0\). Since \(\vec v_2\) does not appear in the combination here, the same coefficients on \(\vec v_1\) and \(\vec v_3\) work, namely \(d=a=-3\) and \(e=c=2\).
$$ \boxed{\,d=-3,\; e=2\,} $$
Geometrically, \(\vec x\) lies in the plane spanned by \(\vec v_1\) and \(\vec v_3\) (the set \(\mathrm{span}\lbrace\vec v_1,\vec v_3\rbrace\)), so we did not need \(\vec v_2\) to reach \(\vec x\). (See next page)
Visual note: In the view above, the arrows for \(\vec v_1\), \(\vec v_3\), and \(\vec x\) look almost colinear only because of the camera angle. What matters is that they are coplanar: \(\vec x \in \mathrm{span}\lbrace\vec v_1,\vec v_3\rbrace\). The arrow for \(\vec v_2\) is not in that plane, which is why we did not need it in the combination. To see this clearly, open the interactive viewer and rotate the scene:
(3 pts) Try and find constants \(p\) and \(q\) such that
$$ p \vec v_1 + q \vec v_2 = \vec x $$
If you are able to find constants \(p\) and \(q\), explain why, even though there are two unknowns but three equations for them. If you are unable to find constants \(p\) and \(q\), explain why no solution exists.
Solution
No solution.
This is a system of three equations in two unknowns, because the linear combination uses only two vectors. We’ll attempt to solve it the same way as in part (a).
Since \((2)\) is violated, the system is inconsistent and there are no constants \(p,q\) satisfying all three equations.
Why this also makes sense visually. From the 3D visualization, \(\vec x\) lies in the plane generated by linear combinations of \(\vec v_1\) and \(\vec v_3\)\(\big(\mathrm{span}\lbrace\vec v_1,\vec v_3\rbrace\big)\). Trying to use only \(\vec v_1\) and \(\vec v_2\) keeps you in the different plane \(\mathrm{span}\lbrace\vec v_1,\vec v_2\rbrace\), which does not contain \(\vec x\). Hence no solution with \(p\vec v_1+q\vec v_2=\vec x\).
$$ \boxed{\text{No solution}} $$
Problem 4: Correlation (7 pts)
In Chapter 2.4, you were told that the correlation coefficient, \(r\), ranges between \(-1\) and \(1\), where \(-1\) implies a perfect negative linear association and \(1\) implies a perfect positive linear association. However, you were never given a proof of the fact that \(-1 \leq r \leq 1\).
Here, you will prove this fact, given your newfound understanding of vectors, the dot product, and angles.
a)
(2 pts) Let \(\vec x\) and \(\vec y\) be two vectors in \(\mathbb{R}^n\). We define the “mean-centered” version of \(\vec x\) to be:
where \(\displaystyle \bar{x} = \frac{1}{n} \sum_{i=1}^n x_i\) is the mean of the components of \(\vec{x}\). The mean-centered version of \(\vec y\), named \(\vec{y}_{\text{c}}\), is defined similarly.
Express \(\vec{x}_{\text{c}} \cdot \vec{y}_{\text{c}}\) using summation notation.
(2 pts) In 1-2 English sentences, explain why the result from part b) implies that \(-1 \leq r \leq 1\).
Solution
The result from part b) implies that \(-1 \leq r \leq 1\) because the right-hand side of the equation is the cosine of the angle between the mean-centered vectors, and the cosine of an angle is bounded between \(-1\) and \(1\).
Problem 5: Projections (15 pts)
In Chapter 3.4, we study the concept of projecting one vector onto one or more other vectors. In this problem, you’ll see how this concept can be thought of in terms of our friend from the first two weeks of the course: calculus.
Let \(\vec x\) and \(\vec y\) be two vectors in \(\mathbb{R}^n\). Consider the function \(f: \mathbb{R} \to \mathbb{R}\), defined as:
$$ f(k) = \lVert \vec y - k \vec x \rVert^2 $$
By \(\mathbb{R} \to \mathbb{R}\), we mean that \(f\) takes in a single real number (i.e. a scalar, not a vector) and outputs a single real number. This means that we can find \(\frac{\text{d} f}{\text{d} k}\), the derivative of \(f\) with respect to \(k\).
Note that \(k \vec x\) is a vector that points in the same direction (or the opposite direction) as \(\vec x\).
a)
(4 pts) Rewrite \(f(k)\) using the properties of the dot product from Chapter 3.3. Then, show that:
$$ \frac{\text{d} f}{\text{d} k} = -2 \vec x \cdot \vec y + 2k \vec x \cdot \vec x $$
Solution
Start by rewriting the squared norm as a dot product and expanding. We color the dot–product pieces to track them: \(\textcolor{orange}{\vec y\cdot\vec y}\) (orange), \(\textcolor{blue}{\vec x\cdot\vec x}\) (blue), and \(\textcolor{magenta}{\vec x\cdot\vec y}\) (magenta).
(2 pts) Find \(k^*\), the value of \(k\) that minimizes \(f(k)\). A second derivative test is not necessary.
Solution
From part a), we know that \(\dfrac{\text{d}f}{\text{d}k} = -2\vec x\cdot\vec y + 2k(\vec x\cdot\vec x)\). Let’s set this derivative to \(0\) and solve for \(k\).
This gives the minimizer when \(\vec x\cdot\vec x>0\). If \(\vec x\cdot\vec x=0\), the only possibility is \(\vec x=\vec 0=\begin{bmatrix}0\\0\\ \vdots\\ 0\end{bmatrix}\). In that case,
$$ f(k)=\|\vec y - k\vec 0\|^2=\|\vec y\|^2 $$
which does not depend on \(k\). Thus every value of \(k\) yields the same objective value, and any \(k\) minimizes \(f\).
(3 pts) Show that the vectors \(k^* \vec x\) and \(\vec y - k^* \vec x\) are orthogonal.
Solution
From part b), \(k^*=\dfrac{\vec x\cdot\vec y}{\vec x\cdot\vec x}\) when \(\vec x\neq \vec 0\). To check whether two vectors are orthogonal, we compute their dot product; they are orthogonal if and only if the dot product equals \(0\).
Since the dot product is \(0\), the vectors \(k^*\vec x\) and \(\vec y - k^*\vec x\) are orthogonal.
d)
(4 pts) Now, let’s study a seemingly unrelated problem. Suppose we’re given a dataset
\((x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\) and we’d like to find the optimal model parameter, \(w\), for a simple linear model with no intercept term,
$$ h(x_i) = w x_i $$
Find the value of \(w\) that minimizes the average loss (i.e. empirical risk) when using squared loss. A second derivative test is not necessary. (To be clear, the solution to this problem does not involve linear algebra.)
Solution
First, let’s start by writing down an expression for mean squared error, \(R_\text{sq}(w)\).
(2 pts) Suppose \(\vec x = \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{bmatrix}\) is a vector of all the \(x_i\) values in the dataset and \(\vec y = \begin{bmatrix} y_1 \\ y_2 \\ \vdots \\ y_n \end{bmatrix}\) is a vector of all the \(y_i\) values in the dataset.
Then, notice that \(w^*\) (the optimal slope) from part d) is the same formula as \(k^*\) (the optimal stretching factor) from part b)! This is not a coincidence: the problem in part d) is equivalent to the problem stated at the start of this question, it’s just stated differently! This may be a bit confusing, since:
The problem at the start involves two vectors, \(\vec x\) and \(\vec y\), which live in \(\mathbb{R}^n\), and \(n\) may be very large (could be 100-dimensional space!).
The problem in part d) involves a dataset of \(n\) points, \((x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\), but the points themselves along with the line \(h(x_i) = w x_i\) are drawn in \(\mathbb{R}^2\).
In the vector view, we’re finding the best scalar multiple of a vector in \(\mathbb{R}^n\) to make it as close as possible to another vector in \(\mathbb{R}^n\). In the regression view, we’re fitting a line (through the origin) to points in \(\mathbb{R}^2\).
Let’s make the connection between the two viewpoints more explicit. In part d), once we pick a value of \(w\), the predictions for each \(x_i\) are of the form \(w x_i\). A vector of predictions, \(\vec p\), might look like:
$$ \vec p = \begin{bmatrix} h(x_1) \\\\ h(x_2) \\\\ \vdots \\\\ h(x_n) \end{bmatrix} = \begin{bmatrix} w x_1 \\\\ w x_2 \\\\ \vdots \\\\ w x_n \end{bmatrix} = w \begin{bmatrix} x_1 \\\\ x_2 \\\\ \vdots \\\\ x_n \end{bmatrix} = w \vec x $$
Given this, in 1-2 English sentences, explain why finding the \(w\) that minimizes
\(\displaystyle R_\text{sq}(w) = \frac{1}{n}\sum_{i=1}^n \big(y_i - w x_i\big)^2\) is equivalent to finding the scalar \(k\) that minimizes
\(\displaystyle f(k) = \lVert \vec y - k \vec x \rVert^2\).
Solution
Minimizing
$$ R_\text{sq}(w) = \frac{1}{n}\sum_{i=1}^n (y_i - w x_i)^2 $$
is equivalent to minimizing
$$ \lVert \vec y - w \vec x \rVert^2 $$
because the vector of residuals has components \(y_i - w x_i\), and squaring and summing those components is exactly the squared Euclidean norm of \(\vec y - w \vec x\). Thus, choosing the best slope \(w\) in the regression problem is the same as choosing the best scalar \(k\) that makes \(k\vec x\) as close as possible to \(\vec y\).
Problem 6: Norms (12 pts)
In the last section of Chapter 3.2, we introduced the concept of vector norms other than the “default” Euclidean norm. Each of those norms describes a different way of measuring the length of a vector — just like how different loss functions described different ways of measuring the error of a prediction.
a)
(2 pts) In this part only, let \(\vec v = \begin{bmatrix} 3 \\ -6 \\ 0 \\ 2 \end{bmatrix}\). Compute \(\lVert \vec v \rVert_2\), \(\lVert \vec v \rVert_1\), and \(\lVert \vec v \rVert_\infty\).
Since \(8\neq 4\), the parallelogram law does not hold for the \(L_1\) norm with this choice of \(\vec u,\vec v\)
c)
(3 pts) Prove that
$$ \lVert \vec v \rVert_2 \leq \sqrt{n}\lVert \vec v \rVert_\infty $$
Hint: Start by writing out the definition of the \(L_2\) norm, and then square it to remove the square root. You will have a sum of \(n\) terms. Explain why each of those \(n\) terms is less than or equal to \(\lVert \vec v \rVert_\infty^2\). This is most of the way to the proof, but there’s still some work you’ll need to do after you get to that point.
As the hint implies, let’s start by expanding the definition of \(|\vec v|_1^2\). We write the \(L_1\) norm as one square to avoid carrying a square root
For intuition, recall the perspective from part (c): by definition, the \(L_\infty\) norm is the largest absolute value among the components, so \(|\vec v|_\infty \ge |v_i|\) for every \(i\), and this remains true after squaring because both sides are nonnegative. Here, we will instead use the hint and expand the \(L_1\) square into “square” terms and “cross” terms
Both sides are nonnegative, so taking square roots preserves the inequality
$$ \|\vec v\|_2 \;\le\; \|\vec v\|_1 $$
Problem 7: Neighbors (10 pts)
This problem involves writing code and submitting it to the Gradescope autograder.
There are two ways to access the supplemental Jupyter Notebook:
Option 1 (preferred): Set up a Jupyter Notebook environment locally, use git to clone our course repository, and open homeworks/hw03/hw03.ipynb. For instructions on how to do this, see the Environment Setup page of the course website.
Option 2: Click here to open hw03.ipynb on DataHub. Before doing so, read the instructions on the Environment Setup page on how to use the DataHub.
To receive credit for the programming portion of the homework, you’ll need to submit your completed notebook to the autograder on Gradescope. Your submission time for Homework 3 is the latter of your PDF and code submission times.
Problem 8: Feedback (6 pts)
We’d like to get your feedback on how the course has been going so far, now that we’re a few weeks in.
You can find the survey at this link. It is not anonymous, but it links to an anonymous feedback form if you’d like to provide some feedback anonymously.
Thank you for your feedback — it’s helping shape our brand-new course.