Each lab worksheet will contain several activities, some of which will involve writing code and others that will involve writing math on paper. To receive credit for a lab, you must complete as many of the activities as you can in 2 hours and submit a PDF of your work to Gradescope. We will provide specific instructions on how to submit programming activities (e.g. submitting the notebook or including a screenshot of some output).
Feel free to work with others in the course, but you must submit individually.
This is the default norm for vectors in \(\mathbb{R}^n\), but other norms exist.
(3.1) A linear combination of the vectors \(\vec v_1,\vec v_2, \dots,\vec v_d\) is any vector that can be written as
$$ a_1\vec v_1 + a_2\vec v_2+\dots+a_d\vec v_d $$
where \(a_1, a_2, \dots, a_d\) are scalars. We can think of this as taking bits of each vector and adding them together. The \(a_i\)’s are called the coefficients of the linear combination.
(3.3) The dot product of two vectors \(\vec u, \vec v \in \mathbb{R}^n\) is defined as:
(3.3) The dot product also has a geometric definition, involving the norms (lengths) of the vectors and the angle between them:
$$ \vec u \cdot \vec v = ||\vec u|| ||\vec v|| \text{cos}\theta $$
(3.3) The key takeaway from the dot product is that it tells us how similar the directions of two vectors are. When two vectors have a dot product of 0, they are orthogonal, or have a 90 degree angle between them.
Activity 1: Linear Combinations
Let \(\vec u = \begin{bmatrix} 4 \\ 3 \end{bmatrix}\), \(\vec v = \begin{bmatrix} -1 \\ -3 \end{bmatrix}\), and \(\vec w = \begin{bmatrix} -6 \\ 9 \end{bmatrix}\).
a)
Find values of \(a\) and \(b\) such that \(a \vec u + b \vec v = \vec w\). By finding \(a\) and \(b\), you have written \(\vec w\) as a linear combination of \(\vec u\) and \(\vec v\).
Solution
We can pose this problem as solving a system of equations. By scalar multiplication, we have:
Now, try and write \(\vec w\) as a linear combination of \(\vec u\), \(\vec v\), and \(\begin{bmatrix} 2 \\ 1 \end{bmatrix}\). In other words, try and find values of \(a\), \(b\), and \(c\) such that
$$ a \begin{bmatrix} 4 \\\\ 3 \end{bmatrix} + b \begin{bmatrix} -1 \\\\ -3 \end{bmatrix} + c \begin{bmatrix} 2 \\\\ 1 \end{bmatrix} = \vec w $$
What happens? Why?
Solution
We can start by trying to solve the corresponding system of equations:
$$ \begin{cases} 4a - b + 2c = -6\\\\ 3a - 3b + c = 9 \end{cases} $$
There are 2 equations and 3 unknowns, which means thare are infinitely many solutions for \(a\), \(b\), and \(c\).
What’s the linear algebra reason for this?
With just \(\begin{bmatrix}4\\3\end{bmatrix}\) and \(\begin{bmatrix}-1\\-3\end{bmatrix}\), you can already create any other vector in \(\mathbb{R}^2\). That is, any vector in \(\mathbb{R}^2\) can be written as a linear combination of \(\begin{bmatrix}4\\3\end{bmatrix}\) and \(\begin{bmatrix}-1\\-3\end{bmatrix}\).
That is, for any vector \(\vec w \in \mathbb{R}^2\) (not just the one in this question), there exist unique values of \(a\) and \(b\) such that
$$ a \begin{bmatrix}4\\\\3\end{bmatrix} + b \begin{bmatrix}-1\\\\-3\end{bmatrix} = \vec w $$
Since \(\begin{bmatrix} 4 \\ 3 \end{bmatrix}\) and \(\begin{bmatrix} -1 \\ -3 \end{bmatrix}\) already can create any other vector in \(\mathbb{R}^2\), adding \(\begin{bmatrix} 2 \\ 1 \end{bmatrix}\) to the linear combination doesn’t “unlock” any new vectors — we can still create any other vector in \(\mathbb{R}^2\).
But, because \(\begin{bmatrix} 2 \\ 1 \end{bmatrix}\) already can be created using \(\begin{bmatrix} 4 \\ 3 \end{bmatrix}\) and \(\begin{bmatrix} -1 \\ -3 \end{bmatrix}\), adding it to the linear combination makes it so that there are infinitely many solutions for \(a\), \(b\), and \(c\) in
$$ a \begin{bmatrix}4\\\\3\end{bmatrix} + b \begin{bmatrix}-1\\\\-3\end{bmatrix} + c \begin{bmatrix}2\\\\1\end{bmatrix} = \vec w $$
If there are infinitely many solutions, how do we find them? Let’s treat \(c\) as a free variable, and solve for \(a\) and \(b\) in terms of \(c\).
$$ \begin{cases} 4a - b + 2c = -6\\\\ 3a - 3b + c = 9 \end{cases} $$
So, the values of \(a\), \(b\), and \(c\) that satisfy
$$ a \begin{bmatrix} 4 \\\\ 3 \end{bmatrix} + b \begin{bmatrix} -1 \\\\ -3 \end{bmatrix} + c \begin{bmatrix} 2 \\\\ 1 \end{bmatrix} = \begin{bmatrix} -6 \\\\ 9 \end{bmatrix} $$
are
$$ \boxed{a = -3 - \frac{5}{9}c, \qquad b = -6 - \frac{2}{9}c, \qquad c = c, c \in \mathbb{R}} $$
\(c\) can be anything, which is why there are infinitely many solutions. If we let \(c = 0\), then we get back \(a = -3\) and \(b = -6\) from part a). But, say, if we let \(c = -9\), then we get \(a = 2\) and \(b = -4\), which also works:
Now, try and write \(\vec w\) as a linear combination of \(\begin{bmatrix} 2 \\ 1 \end{bmatrix}\) and \(\begin{bmatrix} -4 \\ -2 \end{bmatrix}\). What happens? Why?
Solution
Note \(\begin{bmatrix}-4\\-2\end{bmatrix}=-2\begin{bmatrix}2\\1\end{bmatrix}\), which means these vectors point in the same direction, or lie on the same line. (The formal term is that these vectors are collinear.)
Since \(\vec w=\begin{bmatrix}-6\\9\end{bmatrix}\) is not a scalar multiple of \(\begin{bmatrix}2\\1\end{bmatrix}\) (ratios \(-6/2=-3\) vs. \(9/1=9\) disagree), no solution exists!
To conclude, because the two vectors \(\begin{bmatrix}2\\1\end{bmatrix}\) and \(\begin{bmatrix}-4\\-2\end{bmatrix}\) are collinear, it is impossible to write \(\vec w\) as a linear combination of them. The only possible linear combinations are of the form \(c \begin{bmatrix}2\\1\end{bmatrix}\) for some \(c \in \mathbb{R}\).
Activity 2: The Dot Product
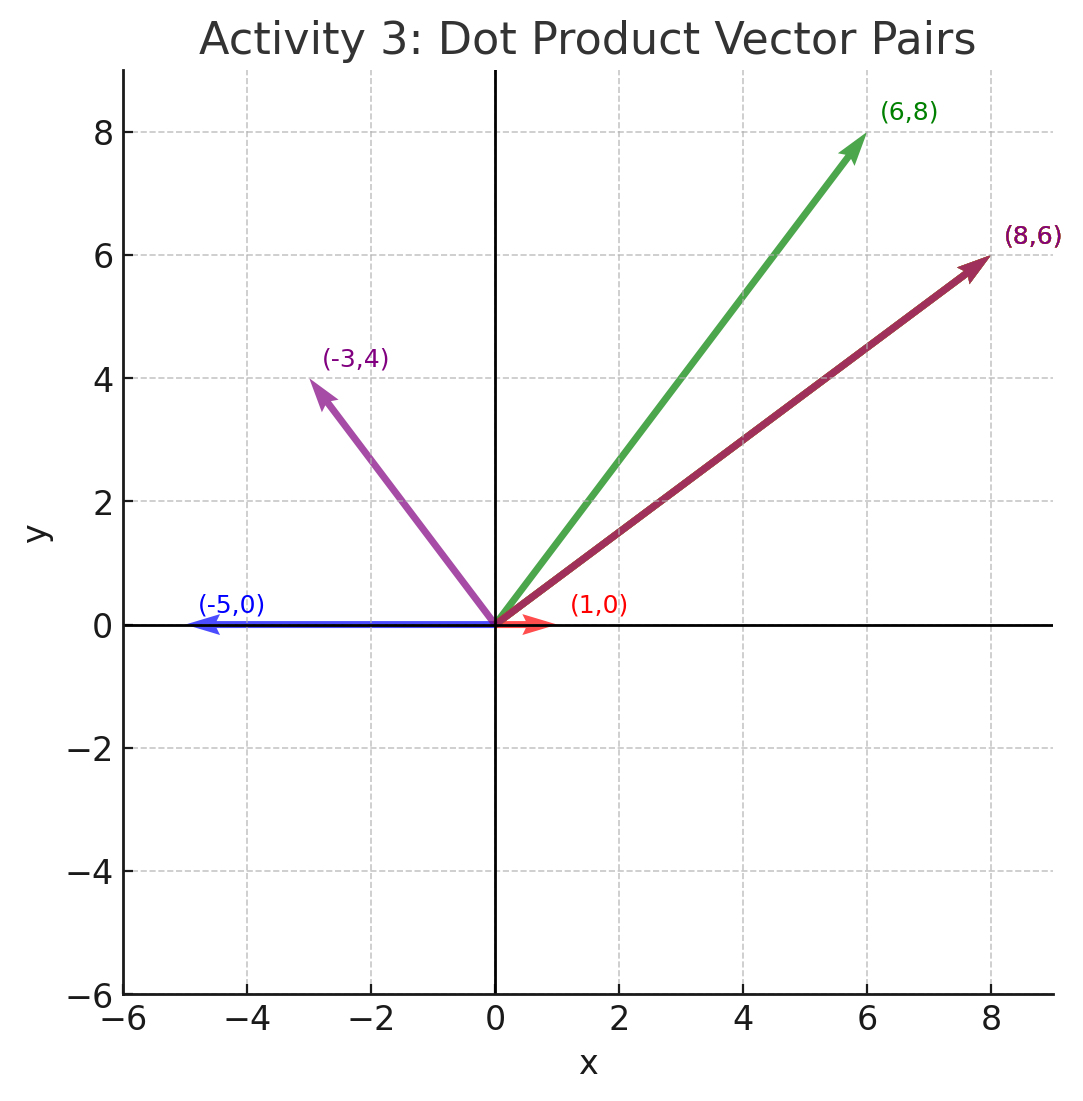
For each pair of vectors below (1) draw them on the grid at the bottom of the page and (2) compute their dot product.
Since the dot product is \(0\), the vectors are orthogonal.
Solution
Activity 3: Angles and Orthogonality
In this activity, we will investigate the relationship between the two definitions of the dot product and learn how to use this equivalence to measure the similarity between two vectors.
so the vectors are orthogonal. Conversely, if \(\vec u\cdot\vec v=0\) (and neither vector is the zero vector), then \(\cos\theta=0\) and \(\theta=90^\circ\).
Activity 4: Sum–Difference Orthogonality
Let \(\vec u=\begin{bmatrix}2\\-1\\0\\5\end{bmatrix}\) and \(\vec v=\begin{bmatrix}1\\2\\4\\-3\end{bmatrix}\).
a)
Show that \(\vec u+\vec v\) and \(\vec u-\vec v\) are orthogonal.
Since the dot product is \(0\), the vectors are orthogonal.
b)
Now suppose \(\vec u,\vec v\in\mathbb{R}^n\) are arbitrary vectors with the same number of components. Is it always true that \(\vec u+\vec v\) and \(\vec u-\vec v\) are orthogonal?
If so, prove why.
If not, specify conditions under which it’s guaranteed that \(\vec u+\vec v\) and \(\vec u-\vec v\) are orthogonal.
Hint: Use the distributive property of the dot product, which states that
$$ (\vec a + \vec b) \cdot (\vec c + \vec d) = \vec a \cdot \vec c + \vec a \cdot \vec d + \vec b \cdot \vec c + \vec b \cdot \vec d $$
Solution
For any two vectors \(\vec u\) and \(\vec v\),
$$ (\vec u+\vec v)\cdot(\vec u-\vec v) = \vec u\cdot\vec u - \vec u\cdot\vec v + \vec v\cdot\vec u - \vec v\cdot\vec v = \|\vec u\|^2 - \|\vec v\|^2, $$
since \(\vec u\cdot\vec v=\vec v\cdot\vec u\).
So, in order for \(\vec u+\vec v\) and \(\vec u-\vec v\) to be orthogonal, we need
$$ \|\vec u\|^2 - \|\vec v\|^2 = 0 $$
which means
$$ \|\vec u\| = \|\vec v\| $$
So, \(\vec u+\vec v\) and \(\vec u-\vec v\) are orthogonal if (and only if!) the two vectors have equal length. That was the case in part a) — both vectors had a norm of \(\sqrt{2^2 + (-1)^2 + 0^2 + 5^2} = \sqrt{30}\).
Activity 5: Triangle Inequality
The triangle inequality states that for any two vectors \(\vec u, \vec v \in \mathbb{R}^n:\)
$$ \lVert \vec u + \vec v \rVert \leq \lVert \vec u \rVert + \lVert \vec v \rVert $$
a)
For the vectors \(\vec u = \begin{bmatrix} 4 \\ 3 \end{bmatrix}\) and \(\vec v = \begin{bmatrix} -1 \\ -3 \end{bmatrix}\), verify that the triangle inequality holds. That is, show that the left-hand side is less than or equal to the right-hand side.
Solution
First, let’s find \(\lVert \vec u + \vec v \rVert\).
So, in this case, the triangle inequality achieves equality. What you’ll notice is that \(\vec x\) and \(\vec y\) point in the same direction, i.e. \(\vec y = 2 \vec x\).
Activity 6: Arrays in NumPy
Instead of writing code in a separate Jupyter Notebook for this lab, you will interact with the code cells that exist in the course notes.
In particular, go to Chapter 3.2 of the course notes, scroll all the way to the bottom, and complete Activity 5 there. Once you’re done, include a screenshot of your completed Activity 5 in your PDF submission of Lab 3 to Gradescope, making sure to include proof that you’ve completed the activity.