How many rows and columns does \(X\) have? What is \(\text{rank}(X)\)?
Lab 12: Singular Value Decomposition
due for completion at 11:59PM Ann Arbor Time on Monday, June 22nd, 2026
Each lab worksheet will contain several activities, some of which will involve writing code and others that will involve writing math on paper. To receive credit for a lab, you must complete as many of the activities as you can in 2 hours and submit a PDF of your work to Gradescope. We will provide specific instructions on how to submit programming activities (e.g. submitting the notebook or including a screenshot of some output).
Feel free to work with others in the course, but you must submit individually.
Activities
- Activity 1: SVD Fundamentals
- Activity 2: Outer Products
- Activity 3: Rotating and Stretching
- Activity 4: PCA Practice
Recap: Singular Value Decomposition (Chapters 10.1 and 10.2)
Suppose \(X\) is any \(n \times d\) matrix. Then, there exists a singular value decomposition (SVD) of \(X\) of the form
$$ X = U \Sigma V^T $$
where:
| Matrix | Shape | Values Come From | Properties |
|---|---|---|---|
| \(U\) | \(n \times n\) | Columns are eigenvectors of \(XX^T\), called the left singular vectors of \(X\) | Orthogonal, \(U^TU = UU^T = I_{n \times n}\) |
| \(\Sigma\) | \(n \times d\) | Each singular value \(\sigma_i\) is the square root of the \(i\)-th largest eigenvalue of \(X^TX\) (or \(XX^T\)) | Diagonal, with value in position \((i, i)\) equal to \(\sigma_i\) for \(i=1,2,\dots,r = \text{rank}(X)\) |
| \(V\) | \(d \times d\) | Columns are eigenvectors of \(X^TX\), called the right singular vectors of \(X\) | Orthogonal, \(V^TV = VV^T = I_{d \times d}\) |
If \(\vec u_i\) and \(\vec v_i\) are the \(i\)-th left and right singular vectors of \(X\), respectively, then \(X\vec v_i = \sigma_i \vec u_i\).
Activity 1: SVD Fundamentals
Suppose the matrix \(X\) has the singular value decomposition \(X=U\Sigma V^T\) where
$$ U = \begin{bmatrix}0 & 1 \\\\ 1 & 0\end{bmatrix}, \quad \Sigma = \begin{bmatrix}\sigma_1 & 0 & 0 \\\\ 0 & 2 & 0 \end{bmatrix}, \quad V = \begin{bmatrix}1/\sqrt{2} & | & 0 \\\\ 0 & \vec v_2 & 1 \\\\ 1/\sqrt{2} & | & 0 \end{bmatrix} $$
a)
b)
Find \(\vec v_2\).
c)
Given that the first column of \(X\) and third column of \(X\) sum to \(\begin{bmatrix}0 \\ 5\end{bmatrix}\), find \(\sigma_1\).
Activity 2: Outer Products
Consider the rank-\(2\) matrix \(X=\begin{bmatrix}1 & 2 & 2 \\ 1 & 3 & 3\end{bmatrix}\).
a)
Write \(X\) as a sum of two rank-1 outer products, e.g. \(X=\vec x_1 \vec y_1^T + \vec x_2 \vec y_2^T\).
b)
Find \(XX^T\) and \(X^TX\), and the trace and determinant of each. Feel free to use numpy.
c)
If \(X\) is any \(n \times d\) matrix, which of the following are guaranteed to be true, and why? Hint: How does the trace of a matrix relate to its eigenvalues? How are the eigenvalues of \(XX^T\) and \(X^TX\) related?
$$ \begin{align*} \text{trace}(XX^T)&=\text{trace}(X^TX) \\\\\text{det}(XX^T)&=\text{det}(X^TX) \end{align*} $$
Activity 3: Rotating and Stretching
Suppose \(X\) is a \(5 \times 2\) matrix with singular value decomposition \(X=U \Sigma V^T\), and that \(\vec v_1\) and \(\vec v_2\) are the first and second columns of \(V\), respectively. Furthermore, suppose \(\vec w \in \mathbb{R}^2\) is a vector such that
$$ \vec w = 3\vec v_1 - \vec v_2 $$
a)
Find \(V^T\vec w\).
b)
Suppose \(X\)’s two singular values are \(\sigma_1 = 10\) and \(\sigma_2 = 3\). Find \(\Sigma V^T\vec w\).
c)
Let \(\vec z = \Sigma V^T\vec w\). In English, what does \(\vec z\) represent, relative to \(\vec w\)?
Recap: Principal Component Analysis (Chapters 10.3 and 10.4)
The goal of principal component analysis (PCA) is reducing the dimensionality of a dataset by constructing new features — called principal components.
These new features are linear combinations of the existing features in the data, and are constructed to minimize the mean squared orthogonal error of the data when projected onto the new features.
As we see in Chapter 10.3, this is equivalent to finding the directions along which the data is most spread out.
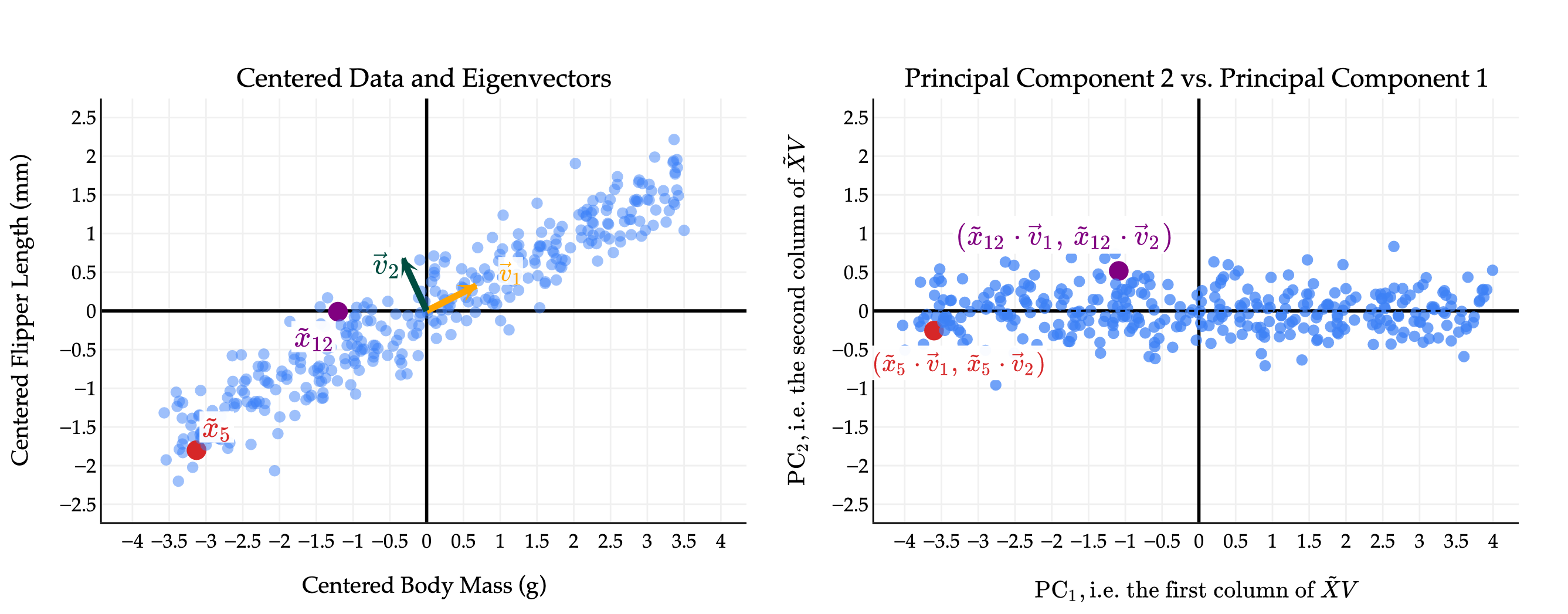
The plot on the left shows the direction vectors \(\vec v_1\) and \(\vec v_2\) which define the first and second principal components, respectively. \(\vec v_1\) is the direction that captures the most variability, followed by \(\vec v_2\). Note that \(\vec v_1\) and \(\vec v_2\) are orthogonal, which results in the principal components (new features) being uncorrelated, as we see in the plot on the right.
The “PCA recipe” is as follows:
Starting with an \(n \times d\) matrix \(X\) of \(n\) data points in \(d\) dimensions and mean-center the data by subtracting the mean of each column from itself. The new matrix is \(\tilde X\).
Compute the singular value decomposition of \(\tilde X\): \(\tilde X = U \Sigma V^T\).
The columns of \(V\) (rows of \(V^T\)) describe the directions of maximal variance in the data! For instance, the single “best direction” is the eigenvector of \(\tilde X \tilde X^T\) with the largest eigenvalue, i.e. \(\vec v_1\) in \(\tilde X = U \Sigma V^T\).
Principal component (new feature) \(j\) comes from multiplying \(\tilde X\) by the \(j\)-th column of \(V\).
$$ \text{PC}_j = \tilde X \vec v_j = \sigma_j \vec u_j $$
- The variance of the new feature is
$$ \text{Var}(\text{PC}_j) = \frac{\sigma_j^2}{n} $$
The proportion of total variance in \(\tilde X\) that is explained by \(\text{PC}_j\) is
$$ \text{proportion of variance explained by PC } j = \frac{\sigma_j^2}{\sum_{k=1}^r \sigma_k^2} $$
Activity 4: PCA Practice
Suppose \(A\), \(B\), and \(C\) are each \(100 \times 2\) matrices, representing \(n=100\) points in \(\mathbb{R}^2\). The three datasets are shown in the scatter plots below. (Matrix \(A\) is in Plot A, matrix \(B\) is in Plot B, and matrix \(C\) is in Plot C.)
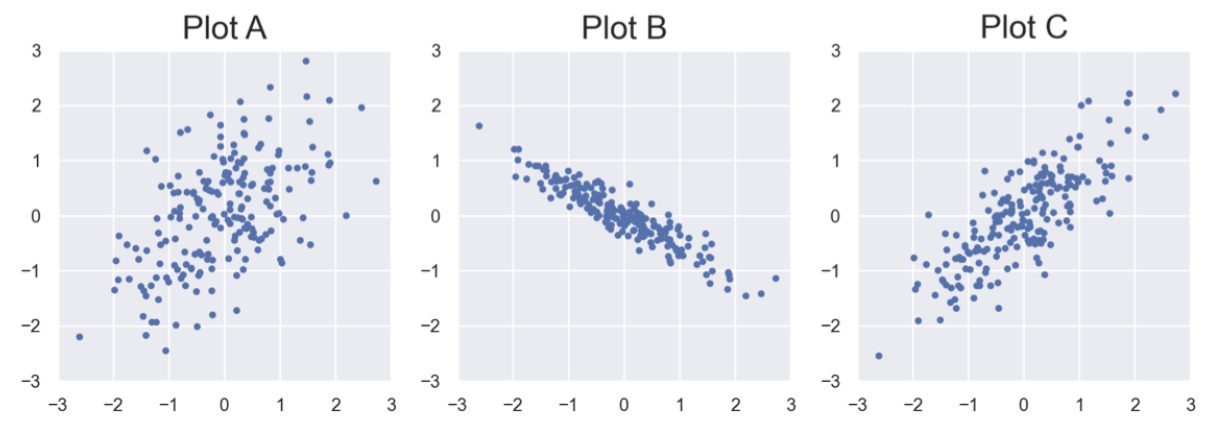
Assume that \(A\), \(B\), and \(C\) are each already mean-centered.
a)
If we applied PCA to each of the above datasets, and created just one principal component in each case, for which dataset would the first principal component have the smallest mean squared orthogonal error — \(A\), \(B\), or \(C\)?
b)
Suppose \(\tilde{X}=U \Sigma V^T\) is the singular value decomposition of \(\tilde{X}\), and that
$$ \Sigma = \begin{bmatrix}16 & 0 \\\\ 0 & 4 \\\\ 0 & 0 \\\\ \vdots & \vdots \\\\ 0 & 0 \end{bmatrix}, \quad \underbrace{V = \begin{bmatrix} 2/\sqrt{5} & 1/\sqrt{5} \\\\ -1/\sqrt{5} & 2/\sqrt{5}\end{bmatrix}}_{\textbf{not } V^T} $$
Which dataset is most likely to be \(\tilde{X}\) — \(A\), \(B\), or \(C\)?
c)
Again, suppose \(\tilde{X}=U \Sigma V^T\) is the singular value decomposition of \(\tilde{X}\), and that
$$ \Sigma = \begin{bmatrix}16 & 0 \\\\ 0 & 4 \\\\ 0 & 0 \\\\ \vdots & \vdots \\\\ 0 & 0 \end{bmatrix}, \quad \underbrace{V = \begin{bmatrix} 2/\sqrt{5} & 1/\sqrt{5} \\\\ -1/\sqrt{5} & 2/\sqrt{5}\end{bmatrix}}_{\textbf{not } V^T} $$
What is the proportion of the total variance in \(\tilde{X}\) that is accounted for by the first principal component?
d)
Suppose that in the graph of principal component 2 vs. principal component 1 (i.e. with PC 1 on the \(x\)-axis and PC 2 on the \(y\)-axis), a particular data point is plotted at \((4, 2)\). What is the corresponding point in the original (mean-centered) dataset? Your answer should be a tuple of two numbers, \((x, y)\) (or equivalently, a vector in \(\mathbb{R}^2\)). Hint: Start by understanding the plot on Page 4.